消息ACK机制
RocketMQ是以consumer group+queue为单位是管理消费进度的,以一个consumer offset标记这个这个消费组在这条queue上的消费进度。
如果某已存在的消费组出现了新消费实例的时候,依靠这个组的消费进度,就可以判断第一次是从哪里开始拉取的。
每次消息成功后,本地的消费进度会被更新,然后由定时器定时同步到broker,以此持久化消费进度。
但是每次记录消费进度的时候,只会把一批消息中最小的offset值为消费进度值,如下图:
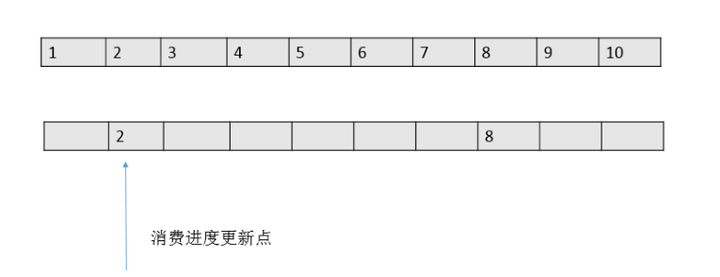
这钟方式和传统的一条message单独ack的方式有本质的区别。性能上提升的同时,会带来一个潜在的重复问题——由于消费进度只是记录了一个下标,就可能出现拉取了100条消息如 2101-2200的消息,后面99条都消费结束了,只有2101消费一直没有结束的情况。
在这种情况下,RocketMQ为了保证消息肯定被消费成功,消费进度职能维持在2101,直到2101也消费结束了,本地的消费进度才会一下子更新到2200。
在这种设计下,就有消费大量重复的风险。如2101在还没有消费完成的时候消费实例突然退出(机器断电,或者被kill)。这条queue的消费进度还是维持在2101,当queue重新分配给新的实例的时候,新的实例从broker上拿到的消费进度还是维持在2101,这时候就会又从2101开始消费,2102-2200这批消息实际上已经被消费过还是会投递一次。
对于这个场景,3.2.6之前的RocketMQ无能为力,所以业务必须要保证消息消费的幂等性,这也是RocketMQ官方多次强调的态度。
实际上,从源码的角度上看,RocketMQ可能是考虑过这个问题的,截止到3.2.6的版本的源码中,可以看到为了缓解这个问题的影响面,DefaultMQPushConsumer中有个配置consumeConcurrentlyMaxSpan
1
2
3
4
|
private int consumeConcurrentlyMaxSpan = 2000;
|
这个值默认是2000,当RocketMQ发现本地缓存的消息的最大值-最小值差距大于这个值(2000)的时候,会触发流控——也就是说如果头尾都卡住了部分消息,达到了这个阈值就不再拉取消息。
但作用实际很有限,像刚刚这个例子,2101的消费是死循环,其他消费非常正常的话,是无能为力的。一旦退出,在不人工干预的情况下,2101后所有消息全部重复。
Ack卡进度解决方案
对于这个卡消费进度的问题,最显而易见的解法是设定一个超时时间,达到超时时间的那个消费当作消费失败处理。
后来RocketMQ显然也发现了这个问题,而RocketMQ在3.5.8之后也就是采用这样的方案去解决这个问题。
- 在pushConsumer中 有一个consumeTimeout字段(默认15分钟),用于设置最大的消费超时时间。消费前会记录一个消费的开始时间,后面用于比对。
- 消费者启动的时候,会定期扫描所有消费的消息,达到这个timeout的那些消息,就会触发sendBack并ack的操作。这里扫描的间隔也是consumeTimeout(单位分钟)的间隔。
核心源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
public void start() {
this.CleanExpireMsgExecutors.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
cleanExpireMsg();
}
}, this.defaultMQPushConsumer.getConsumeTimeout(), this.defaultMQPushConsumer.getConsumeTimeout(), TimeUnit.MINUTES);
}
private void cleanExpireMsg() {
Iterator<Map.Entry<MessageQueue, ProcessQueue>> it =
this.defaultMQPushConsumerImpl.getRebalanceImpl().getProcessQueueTable().entrySet().iterator();
while (it.hasNext()) {
Map.Entry<MessageQueue, ProcessQueue> next = it.next();
ProcessQueue pq = next.getValue();
pq.cleanExpiredMsg(this.defaultMQPushConsumer);
}
}
public void cleanExpiredMsg(DefaultMQPushConsumer pushConsumer) {
if (pushConsumer.getDefaultMQPushConsumerImpl().isConsumeOrderly()) {
return;
}
int loop = msgTreeMap.size() < 16 ? msgTreeMap.size() : 16;
for (int i = 0; i < loop; i++) {
MessageExt msg = null;
try {
this.lockTreeMap.readLock().lockInterruptibly();
try {
if (!msgTreeMap.isEmpty() && System.currentTimeMillis() - Long.parseLong(MessageAccessor.getConsumeStartTimeStamp(msgTreeMap.firstEntry().getValue())) > pushConsumer.getConsumeTimeout() * 60 * 1000) {
msg = msgTreeMap.firstEntry().getValue();
} else {
break;
}
} finally {
this.lockTreeMap.readLock().unlock();
}
} catch (InterruptedException e) {
log.error("getExpiredMsg exception", e);
}
try {
pushConsumer.sendMessageBack(msg, 3);
log.info("send expire msg back. topic={}, msgId={}, storeHost={}, queueId={}, queueOffset={}", msg.getTopic(), msg.getMsgId(), msg.getStoreHost(), msg.getQueueId(), msg.getQueueOffset());
try {
this.lockTreeMap.writeLock().lockInterruptibly();
try {
if (!msgTreeMap.isEmpty() && msg.getQueueOffset() == msgTreeMap.firstKey()) {
try {
msgTreeMap.remove(msgTreeMap.firstKey());
} catch (Exception e) {
log.error("send expired msg exception", e);
}
}
} finally {
this.lockTreeMap.writeLock().unlock();
}
} catch (InterruptedException e) {
log.error("getExpiredMsg exception", e);
}
} catch (Exception e) {
log.error("send expired msg exception", e);
}
}
}
|
通过源码看这个方案,其实可以看出有几个不太完善的问题:
- 消费timeout的时间非常不精确。由于扫描的间隔是15分钟,所以实际上触发的时候,消息是有可能卡住了接近30分钟(15*2)才被清理。
- 由于定时器一启动就开始调度了,中途这个consumeTimeout再更新也不会生效。